
ペンギン(African Penguin)実験(「移調」実験)
例えば、5cmと10cmの線分を提示し、5cmの線分を選択する訓練を行った場合、5cmを選択することを学習するのか、あるいはより短い方を選択することを学習するのか?前者は、絶対的な長さに基づいた学習、後者は相対的な選択の学習になります。もし、相対的な選択が学習されていれば、5cmとそれより短い3cmを同時に提示すると、相対的に短い3cmを選択するはずです。このような相対的な選択は「移調」と呼ばれます。5cmと10cmでは相対的に短い5cmを選択するという行動が3cmと5cmという別の組み合わせでも生じ、相対的に短い3cmを選択するという現象を指します。下記の実験では、ペンギンにも「移調」があることが確かめられました。

ケープペンギン(八景島シーパラダイス)

全景


正面パネル

給餌装置(フィーダー)
装置:ペンギン用スキナーボックス(ケージ)
視覚刺激(線分:弁別刺激)はLCDモニターで提示し、 餌(強化子)はターンテーブルをステッピングモータで回転して、正面パネル下の開口部から食べられるようになっています。強化子提示時には、クリッカー音をスピーカーから流し、クリッカートレイニング(条件性強化子訓練)を行います。最終的には、実際の餌(コアジ)を使った強化とクリッカー音だけの条件性強化をミックスした弁別訓練に移行する予定です。刺激提示、強化子の提示等の実験制御および反応の記録は、ノートブックPCとUSBを経由したI/Oボックスで行います。


スキナーボックスの中のケープペンギン
シェイピング初日
動物のオペラント条件づけでは、通常、マガジン訓練(強化子(餌)を食べる練習)から始まります。実験箱に入れられた当初は、慣れない環境下で、ちょったした音でも驚き、なかなか強化子が提示されても食べないものです。何日かかけて実験箱に慣らせ、提示されたらすぐに餌を食べるように訓練します。
今回の実験には4羽のケープペンギンを提供して頂きましたが、この中の2羽はイルカショーに脇役で登場し、とても人慣れしています。一方、残りの2羽はあまり人慣れしておらず、実験が行われる部屋につれてこられた直後は餌を手で与えても全く食べないという状況です。
初日は、良く慣れた個体(ゴエモン)のシェイピング(このページ下の解説1を参照)を試みました。実験箱に入れるとすぐに強化子を食べるので、マガジン訓練の必要はありませんでした。装置の開発時に問題になった、フィーダーが動くということもなく、提示されるとすぐに食べる状態です。ただ、一つ問題が見つかりました。一日にコアジを10匹ぐらいしか食べないので、1匹まるまる与えていたのでは強化数が少なくなるので、小さく切った魚を与えることにしたのですが(下の写真参照)、頭の部分はスムーズに食べられるのですが、しっぽなど他の部分は、飲み込むのに大変苦労していました。先がとがっていないと上手く飲み込めないのかも知れません。明日は、餌を斜めに切って試してみることになりました。
シェイピングの後半に一度つつき反応が生じ、一両日中にはシェイピングが完成すると思われます。


シェイピング:訓練したい反応を徐々に形成するやり方の一種。その時点で生じている反応の内、最も訓練したい反応に近い反応が生じたら強化子を提示し、その反応の頻度が増加したら、より訓練したい反応に近い反応のみを強化するというように、徐々に基準を変えていき、最終的に訓練したい反応のみを強化する。上記の実験では、パネルに対するつつき反応を形成したいので、頭を上げたら強化→パネルを見たら強化→パネルに近づいたら強化→パネルをつついたら強化というように、徐々に反応を形成していきます。このとき気をつけるべき3原則があります。1)スモールステップ:徐々に課題の困難度を高める。急に課題を難しくしたりしない2)即時強化:望ましい行動が生起したら、即時に何らかの結果(褒美などの強化)を与える。3)被験者ペース:実験者あるいは訓練者のペースではなく、被訓練者のペースで行う。
シェイピング2日目 昨日の続きでゴエモンのシェイピングを行いました。後半はつつき反応が形成され、ほぼシェピングは完成間近です。問題は、昨日と同様、頭の部分はスムーズに食べられるのですが、しっぽなど他の部分は、飲み込むのに大変苦労していました。餌を斜めに切って試してみることにしていたのですが、手違いで明日に持ち越しました。


次に、この個体もショーに参加していて、人慣れした”ソラ”のシェイピングを行いました。この個体は、ゴエモンと違って、頭以外でも比較的容易に摂取していました。反応形成は未完成です。


通常、実験の前と後で、強化子の摂取量を計測するためおよび、動因レベルの測定、あるいは健康維持のための目安として体重を測定します。実験後の体重から実験前の体重を引くと、実験時の強化子の摂取量が分かります。もし、基準値に達しなければ、補完的に餌を与えます。
この種の実験では、ある程度おなかが空いていなければ強化子(餌)の効果がありませんので、実験時に主に摂取するように管理を行うことがあります。デンショバトの場合は、自由に餌を摂取しているときの体重(アドリブ体重と呼びます)の80-90%に体重を統制してから実験を行います。セキセイインコやキンカチョウなどの小鳥の場合は代謝率が高いので、85-95%に統制したり、時間制限により動因操作を行ったりします。上記のペンギンの場合は、一日250gと決まっていますので、その値にあわせて強化子を与えます。
体重の計り方ですが、ニホンザルや手乗りではないセキセイインコのように逃げてしまう種の場合は、ケージに入れたまま測定し、後でケージの重さを引いて体重を算出します。ハトの場合は、特殊な量り方があります、羽を交差させると身動きできなくなりますので、その状態で量りに乗せ測定します。ペンギンの場合は、人慣れした個体は誘導すると自ら体重計に軽くジャンプして乗ります(上の写真参照)。
シェイピング完成
ゴエモンのシェイピングが完成しました。相変わらず、しっぽは頭に比べて食べるのが大変そうですが、パネルに対するつつき反応が形成されました。下の写真をクリックすると、反応しているゴエモンの動画を見ることが出来ます。現在は、左右のパネルのどちらをつついても強化されますが、明日からは、左右どちらかだけにターゲット(黒四角)を提示し、提示されている側のパネルをつついたときだけ強化する訓練を行います。動画を見ると分かりますが、ゴエモンは左のパネルを主につついています。左の反応を長く強化すると、将来、強化率が落ちたときに、過去に強化されていた反応が再出現する”Resurgence of responding”(参考文献参照)が生じる可能性がありますので、早めに左への選好を消去する必要があります。
ゴエモンは、餌が回転して完全に出てくる前に、餌が提示される開口部にくちばしをつっこんで食べようとしています。また、反応中および餌をくわえるときに、開口部を確保するために設置した突起部に、左の羽(フリッパー)をのせています。


”ソラ”のシェイピングはまだ完成していません。
参考文献
Epstein, R. (1983). Resurgence of previously reinforced behavior during extinction. Behaviour Analysis Letters, 3, 393-397.
Epstein, R. (1985). Extinction-induced resurgence preliminary investigations and possible applications. The Psychological Record, 35,143-153.
Epstein, R., & Skinner, B. F. (1980). Resurgence of responding after the cessation of response-independent reinforcement. Proceedings of the National Academy of Science of the USA, 77(10), 6251-6253.
刺激トラッキング訓練
ゴエモンのシェイピングが完成しましので、視覚刺激に対する反応の訓練を始めました。今日は、24回反応した内の17回は刺激に反応しました。計算したところ統計的には(Fisherの直接確率計算法)、偶然に反応した確率は約20%で、初日にかかわらず、視覚刺激への反応を学習しつつあることが分かります。
下の写真を見て分かるように、四角の刺激に対してくちばしを開いて反応しています。いかにも視覚刺激そのものを「食べている」ように見えます。

強化子によって、反応の型(response topography)が異なることが知られています。デンショバトで水を強化子にした場合、視覚刺激に対していかにも水を飲むようにくちばしを閉じて反応するのに対して、トウモロコシなどの穀物を強化子にした場合、いかにも食べているようにくちばしを開いて反応します(参考文献参照)。
参考文献
Hearst, E., & Jenkins, H. M. (1974). Sign-tracking: The stimulus-reinforcer relation and directed action. Austin, TX: Psychonomic Society.
反応トポグラフィーとオペラント
デンショバトはつつき反応、ラットはてこ押し反応というように、オペラント研究では設定される反応がほぼ決まっています。この理由は、その種にとって行いやすいあるいは、強化子によって形成されやすい反応があるからです。しかし、オペラント条件づけは万能ではありません。強化子の選択によっては、反応の形成、維持、制御が困難な場合があります。ハムスターの例ですが、穴掘り反応や壁をひっかく反応は、餌を強化子とした場合は容易に制御可能ですが、ハムスターが良く行う洗顔反応(グルーミング)を餌で制御するのは困難です。洗顔反応が生じた直後に餌を提示しても、洗顔反応の頻度(回数)は増加しません(参考文献参照)。洗顔反応を行って、餌を手に入れると言うことは自然の状況下ではほとんどあり得ません。生物学的に、関連性がないと条件づけは難しいと言うことです。
ペンギンの実験を始めるとき、どの反応を用いるのか考えました。ペンギンは新たな被験体なので、前例が無く、どの反応がよいのか分からなかったからです。いろいろ八景島シーパラダイスの方にお聞きしたところ、やはりつつき反応が良いという結論になりました。次に気になったのは、ペンギンのつつき反応の強さはどれくらいかということです。つつき反応の強度が弱い場合は、反応を検出するマイクロスイッチの感度を上げ、そのストローク(反応の距離)を短くする必要があるからです。実際やってみると、杞憂に終わりました。かなり、強い力で反応しました。
行動分析学では、反応とオペラント反応とは厳密な意味で異なります。ここで言う反応とは、反応トポグラフィー(反応の型)のことです。パネルについているマイクロスイッチをONにするためには、くちばしでつついても良いし、ヒレでたたいても構いません。この二つの反応は見かけが違います。このように見かけが違う反応は、反応トポグラフィーが違うと言います。一方、オペラント反応とは、同一の結果を伴う反応の集合のことで、足で押そうと、ヒレで叩こうと、くちばしでつつこうと、同じ結果(餌を手に入れる)を伴うので、同じオペラント反応です。

参考文献
Shettleworth, S.J. (1975). Reinforcement and the organization of behavior in golden hamsters: Hunger, environment, and food reinforcement. Journal of Experimental Psychology: Animal Behavior Processes, 1, 56-87.
クリッカートレイニング
今回のペンギンの訓練では、クリッカートレイニング(条件性強化子訓練)を用いています。当初は、八景島シーパラダイスのショーに役立てるためという目的でしたが、今は、この実験には無くてはならい訓練になりました。その理由は、実験で提示できる強化子(コアジ)の数が限られているからです。この実験に参加しているペンギンは、一日250gと決められているということを以前書きましたが、この値は、一日の量で、実験中に全て与えられるわけではありません。健康維持のため、ビタミン剤や必要があれば各種の薬を投与しなければなりません。ビタミン剤などを投与するには、そのまま与えるのではなく、餌に埋め込んで投与します。その餌を除くと、実験に使用できる餌の量は、約200gぐらいになります。コアジの匹数で言うと、7から8匹ぐらいです。現在実験では、頭としっぽに2等分して与えています。当初3等分して与えたことがありますが、ゴエモンはどうも真ん中およびしっぽの部分を食べるのが苦手のようで、現在は、2等分したものを与えています。ソラは、3等分したものでも問題なく食べていますが、将来、条件を統一するため、強化子(餌)の数が少ないゴエモンにそろえることになりますので、せいぜい14強化(匹数で言うと7匹)しか与えられません。これでは、試行数が少なく、訓練に支障が出るので、実際に強化子そのものを与えないでも強化できる方法が必要です。それが、条件性強化子訓練(クリッカートレイニング)です。
条件性強化子訓練は、強化子(餌)そのものを与える直前に、何らかの刺激(音や視覚刺激)を提示することを繰り返して、強化子そのものを提示しなくても、反応を強化できるようにする訓練です。犬の訓練では、望ましい反応(例えば、お座り)をした場合、褒美の餌を与える直前に、クリッカー音(カチッという音)を与えることを繰り返します。そうすると、餌を与えなくても、望ましい反応を行ったときにクリッカー音を鳴らすだけで、その望ましい反応を続けさせることが出来ます。ただ、クリッカー音(条件性強化子)の効力を維持するため、時々は、クリッカー音の直後に強化子そのもの(一次性強化子:餌)を与える必要があります。
条件性強化子の人間社会における例としては、お金があります。紙のお金(紙幣)は、食べることも出来ないし、たき火に使うにはすぐに燃え尽きてしまいます。ものとしては(物理的には)、単なる精巧な印刷が施された紙にすぎません。しかし、あること(例えば、労働)を行って、それに対して紙幣が与えられると、我々は、その労働を次回も行います。それはなぜかというと、その紙幣で、望みのもの(食料など)と交換できるからです。時間的な流れで言うと、労働を行う→お金をもらう→食べ物を買う(手に入れる)という順になります。この流れは、つつく→クリッカー音が提示される→コアジが食べられるという流れの今回の訓練と同じです。このような意味で、人のお金と今回のゴエモンやソラのクリッカー音は同様な機能を持っています。現在、視覚刺激をつつく訓練を行っていますが、強化子をのせたターンテーブルが回転し始める直前に、クリッカー音をスピーカーから提示しています。十分正確に反応する様になった後に、実際の強化子(コアジ)の提示と、クリッカー音だけの提示をミックスした訓練に移行します。
Breland夫妻が、人のお金と同様な状況でブタの訓練を行ったことがあります。ブタを訓練して、木製のコインを何枚か貯金箱に入れると、餌がもらえるようにしました。人が働いてお金を手に入れ、最終的に食べ物などの必要なものと交換することと同じです。訓練当初は難なくコインを運んでいって貯金箱に入れ、餌を手に入れるということを行っていました。ところが、長期にわたってこの訓練を行っていると、最初は急いでコインを貯金箱に入れていたのが、そのうち、コインを鼻でもてあそぶようになり、なかなか貯金箱に入れようとはしなくなりました。このもてあそぶ反応は、ブタが餌を探して手に入れる反応そのものでした。長期の訓練により、条件性強化子(ここでは木製のコイン)そのものに対して、強化子(餌)に対する反応と同じ反応が出てきてしまい、結果的に強化子そのものを手に入れられなくなったということです。この様に、条件性強化子に対して、生得的(本能的)な反応が生じることを彼らは、本能的逸脱(instinctive drift)と呼んでいます(ページ下の参考文献参照)。
今回の実験では、条件性強化子そのもへ反応することはないので、本能的逸脱は生じないと考えられます。

参考文献
Breland, K., & Breland, M. (1961). The misbehavior of organisms. American Psychologist, 16, 681-684.
刺激トラッキング訓練とクリッカートレイニング
左右どちらかに黒い四角が提示され、その四角が提示された側のパネルをつつくと強化されます。また、強化子(コアジ)が提示される直前にクリッカー音を提示します。ほぼ100%視覚刺激(黒四角)が提示された側のパネルに反応するようになりましたので、次は、試行数を増やすため、クリッカー音だけを提示して、強化子そのものは提示しない試行を加えた訓練へ移行します。
どちらのパネルに反応しても強化された条件(進捗状況3の動画参照)と比べて、立つ位置が中央になった点と、左の羽(フリッパー)を正面パネルの突起部に置かなくなったことが分かります。どちらに提示されるか分からない黒四角をつつくためには、中央にいた方が反応がやりやすくなります。条件の変化に対応して、反応が変化しています。
オペラント条件づけでは、いつどんなときに(先行条件)、どうしたら(反応)、どうなるか(結果)という3つの要因によって学習(条件づけ)が形成されます。
ゴエモンの条件づけでは、反応形成直後、正面に2つの黒い四角が提示され(先行条件)、どちらかをつつくと(反応)、コアジが食べられた(結果)のに対して、現在は、正面のどちらかに1つの黒い四角が提示され(先行条件)、提示された方のパネルをつつくと(反応)、餌がもらえます(結果)。もし、提示されていない方のパネルをつつくと(反応)、何ももらえません(結果)。
反応形成直後と、現在の3つの要因(先行条件ー反応ー結果)は違っています。その結果、ゴエモンは、黒い四角が提示されたパネルだけをつつくようになり、また、左側だけをつつくと強化されない場合があるので、中央に立って反応するようになっています。このように、ゴエモンは、3つの要因(先行条件ー反応ー結果)の組み合わせに敏感で、反応をかえています。人の例では、例えば、授業中に先生に指名された時(先行条件)、答えたら(反応)、ほめられた(結果)。ところが授業中に先生に指名されていないとき(先行条件)、答えたら(反応)、怒られる(結果)。この様に、同じ行動を行っても、先行条件が異なれば、ほめられることもあるし、怒られることもあります。ほめられれば、同じ先行条件であれば次回も進んで同じ反応をするようになり、怒られたときはその様な行動は行わないようになります。
ヒトや動物の行動は、3つの要因(先行条件ー反応ー結果)の関係を調べるとよく分かる場合があります。この3つの要因のつながりを、行動分析学では三項随伴性(Three-term contingency)と呼んだり、行動随伴性と呼んだりします。オペラント条件づけは、この三項随伴性をいろいろアレンジすることで、望ましい反応を増やしたり、望ましくない反応を減らしたりすることが出来ます。
行動分析学研究の枠組み
「3項随伴性」に基づいて、行動の分析を行う。
3項随伴性とは、「弁別刺激」 - 「反応」 - 「反応結果」の3つの項からなる連鎖のことである。弁別刺激とは、個体を取り巻く外的環境の中で、特定の反応を行うときの手がかりとなりうる刺激のことである。ある特定の刺激(弁別刺激)下である反応を行うと、何らかの結果が生じる。反応によって生じた結果が、その個体にとって有利あるいは好ましいものであれば、その弁別刺激の下では、その反応を以前にも増して行うようになる。一方、結果が不利あるいは好ましくない場合は、その反応を以前より行わなくなる。ヒトあるいは動物の行動は、この3項随伴性によって制御されている。
この3項随伴性は、「先行条件(Antecedent events)」-「行動(Behaviour)」-「結果(Consequences)」とも表され、英語の頭文字をとって、A-B-Cと表現されることもある。この3項随伴性にもとづいた分析をABC分析ともよぶ。
ただし、言語などにおいては、同じ単語でも文脈によって意味が変化することがあるので、弁別刺激の前にさらに、文脈刺激あるいは条件性弁別刺激を加えた、4項随伴性によって分析を行う場合がある。
前述したように、現在の随伴性によってのみ、その時の行動が制御されるわけではなく、過去に経験した随伴性もその時の行動に影響を与える。
実験者が個体に対して弁別刺激や反応結果を設定して、反応を形成・修正することを、オペラント条件づけという。
ゴエモンは良くなれていて、ショーに参加する仲間がいるところから、エレベータに乗って下の階の実験室に歩いてやってきます。実験室では、体重計に軽くジャンプして飛び乗り、その後、実験箱に自ら入ります。
試行間間隔中の反応による試行開始の遅延
現在、ゴエモンは試行数を増やすため、実際の強化(餌:コアジ)とクリッカー音の同時提示に、クリッカー音だけを提示するクリッカートレイニングを行っています。この訓練の前に、まずは視覚刺激が提示された側のパネルに対して反応する(つつく)訓練を行いました。このとき、刺激が提示される前(この時間を試行と試行の間ということで、試行間間隔(ITI: Inter-trial Interval)と言います)に、どちらかのパネルをつつき始め、そのままつつき続けるために、刺激が提示されていない側のパネルを誤ってつついてしまうということがありました。このため、この試行間間隔中の反応をなくす(消去する)ため、試行間隔中(刺激が提示されていない間)に反応があった場合は、その時点からさらに2秒間刺激の提示を遅らせる(遅延する)手続きを導入しました。これを導入したとたん、刺激が提示された側のパネルをつつく正反応率は100%になりました。
今回の手続きは、スキナーボックスを利用したオペラント条件づけで良く用いられます。この手続きを導入しないと、試行間間隔中の反応がなかなか無くならないばかりか、逆に増えることがあります。この理由は、たまたま刺激が提示されていない試行間間隔中に反応したら、その直後刺激が提示され、その刺激に反応し、強化される(餌がもらえる)というつながりによって生じます。試行間間隔中から続けて反応していると、少なくとも2回に一回は強化されます。例えば、右側のパネルをつつき続けていると、右側に刺激が提示される試行の場合は、そのつつき反応が強化されます。反応は、必ず強化されなくても2回に1回や、3回に1回など、部分的に強化される場合でも維持されます(反応が生じ続けます)。この強化のやり方については、後日詳しく説明します。
たまたま反応したら強化されたために、その反応が生じ続けるという現象を、行動分析学では「迷信行動(Superstitious Behavior)」と呼びます。この現象を最初に実験的に報告したのは、Skinner (1947)です。その後、この実験に対する批判として、Staddon & Simmelhag (1971)の実験、さらにその批判として、ヒトの迷信行動実験(駒澤大学の小野先生)が発表されています。これも後日機会があったら詳しく説明したいと思います。
今回の実験においては、試行間間隔中の反応をやめさせる必要があったわけですが、反応をやめさせるやり方としては、反応すると嫌なことが生じる「罰」や、何の結果もその反応に後続させない「消去」、さらにはその反応を行っていないときにのみ強化される「他反応分化強化」などのやり方があります。塀に落書きをしたら、おじいちゃんにこっぴどく怒られたため、その後は二度と落書きはしなくなったという例は、罰になります。彼がだじゃれを言ってばかりで、つまらないのでやめさせたい。だじゃれを言うたびに「やめてよ!」と言ってもなかなかやめない。こういう場合は、だじゃれを言うことに対して、彼女がいちいち反応してくれる、このことが実は彼にとっては、かまってくれると言うことで逆に強化になっている場合があります。そのため、だじゃれがなかなか無くならないわけです。このような場合は、だじゃれを言っても完全に無視するに限ります。無視するというやり方は、だじゃれを言うことに対して何の結果も与えない「消去」にあたります。この方法を使うとだじゃれは言わなくなります。他反応分化強化は、やめさせたい反応と同時には出来ない反応を強化して増やし、その結果としてやめさせたい反応の頻度を減少させるやり方を言います。おしゃべりの回数や時間を減らす場合は、何かおしゃべり以外のことをやっているとき強化します。
これらに加えて、反応を減らすやり方として、強化の遅延があります。反応してもすぐには強化を与えないと、反応の頻度は急激に低下します。今回の手続きは、これにあたります。試行間間隔中に反応すると最低2秒間は試行が開始されず(刺激が提示されず)、反応するたびに試行の開始が2秒間遅延されます。
この種の、望ましくない反応に対する遅延手続きの代表的なものには、切り換え反応による強化の保留(COD: Changeover delay)があります。オペラント条件づけを利用した選択実験では、一般的に、反応する対象(オペランダムと呼ぶ)が2つ用意され、一方のオペランダムに反応すると、例えば、平均して10回に1回強化され、別のオペランダムに反応すると例えば5回に1回強化されるというようになっていて、それぞれのオペランダムに何回反応するかその相対頻度を測定します。通常は、この例の場合は、一方が10回に1回、他方が5回に1回なので、強化比は1対2になります。強化比が1対2の場合は、反応比も1対2になることが知られています(Herrnstein, 1961)。これを強化の対応法則(Matching law)と呼びます。ところが、強化の対応法則からはずれて、両者の反応率にあまり差が無くなることがあります。この様な場合、2つのオペランダムに対して交互に反応するパターンが見られます。一方のオペランダムに反応して、他方に反応したところ偶然強化されることがあるため、その交互に反応する反応パターンそのものが強化されたためと考えられます。この交互に反応する反応パターンを減少させる手段がCODです。通常、一方のオペランダムに反応してから別のオペランダムに反応した場合、最低2秒ほど強化子(餌など)を提示しないという手続きです。CODを導入すると、強化の対応法則にほぼ従った反応比(選択比)になります。
参考文献
迷信行動については
Ono, K. (1987). Superstitious behavior in humans. Journal of the Experimental Analysis of Behavior, 47, 261-271.
Skinner, B. F. (1947). ‘Superstition’ in the pigeons. Journal of Experimental Psychology, 38, 168-172.
Staddon, J. E. R., & Simmelhag, V. L. (1971). The superstition experiment: A re- examination of its implications for the principles of adaptive behavior. Psychological Review, 78, 3-43.
CODについては
Baum, W. M. (1982). Choice, changeover, and travel. Journal of the Experimental Analysis of Behavior, 38, 35-49.
Catania, A. C. (1962). Independence of concurrent responding maintained by interval schedules of reinforcement. Journal of the Experimental Analysis of Behavior, 5, 175-184.
Krageloh, C. U., & Davison, M. (2003). Concurrent-schedule performance in transition: Changeover delays and signaled reinforcer ratios. Journal of the Experimental Analysis of Behavior, 79, 87-109.
真辺 一近・河嶋 孝 (1982). 信号キイ手続きにおける切り換え反応による強化の保留の効果 心理学研究,53,304-307.
Shull, R. L., & Pliskoff, S. S. (1967). Changeover delay and concurrent schedules: Some effects on relative performance measures. Journal of the Experimental Analysis of Behavior, 10, 517-527.
強化の対応法則については
Herrnstein, R. J. (1961). Relative and absolute strength of response as a function of frequency of reinforcement. Journal of the Experimental Analysis of Behavior, 4, 267-272.
反応キィトラブル
ゴエモンの訓練は順調に進み、クリッカー音のみの提示が80%、クリッカー音と一次性強化子(実際の強化子:コアジ)の同時提示が20%の条件性強化訓練に到達しました。ところが、訓練の後半から、反応しても(つついても)マイクロスイッチがONにならず、なかなか強化されないという事態が生じました。この日の前も同様なことが起きたらしく、村田さんから、スイッチがかたくなって反応が検出できなくなり、しばらくすると元通りスムーズになるという報告を受けました。
下に、つつき反応を検出する反応パネルの図を示しました。ゴエモンがモニターに提示されている刺激を透明アクリル越しにつつくと、アクリル板が押され、裏側に取り付けられたマイクロスイッチがONになります。くちばしをアクリルパネルから離すと、マイクロスイッチに内蔵されたバネによって、元の位置にアクリルパネルは戻されます。この位置では、スイッチはOFFになります。真下の図は、OFFの状態です(注:わかりやすくするため、マイクロスイッチは実際の大きさよりかなり大きめに描いてあります)。


反応キィがかたくなる原因として考えられることは、ヒンジに異物が挟まってかたくなることや、マイクロスイッチが繰り返しON/OFFしたことで、バネが折れたり、破片が詰まったりする場合が考えられます。ただ、しばらくすると元に戻ると言うことは考えにくいことでした。これが、その時だけなら、異物が取れて元に戻ったことが考えられますが、何度もかたくなり、再び元に戻ることは考えにくく、謎でした。目視の結果も、ヒンジやマイクロスイッチには問題はありませんでした。
さて、この謎を解く鍵は、強化子(餌)にありました。ただし、ちぎれた餌が透明アクリルと正面パネルの間に挟まったわけではありません。
反応キィトラブル2
ペンギンの強化子としてはコアジを使っていますが、コアジはターンテーブルに並べる前に、腐敗を防ぐため氷水に浸した状態でプラスチックのバケツで実験室まで運んできます。そしてそのまま取り出してターンテーブルに乗せるので、かなりぬれています。また、コアジの体内にもかなりの水分が含まれています。ペンギンは、鵜と同じように、魚を丸飲みするのですが、時々くちばしから余分な水を流したり、首を振って水分を飛ばしたりします。
実は、この水が今回の反応キィがかたくなる原因でした。この水のせいでヒンジやマイクロスイッチがさびたからではありません。ヒンジはプラスチックで出来ています。
下の図をご覧ください。水が伝わる経路を赤の矢印で示しています。
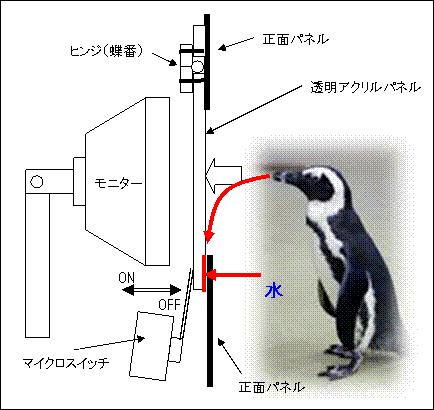
ゴエモンの口から出た水が、透明アクリルパネルを伝わって正面パネルとの隙間にしみこんでいたのです。このため、表面張力が発生し、透明パネルが正面パネルにくっついてしまっていました。この水が乾くと、元通りスムーズに動いていたのです。
応急処置として、近くにあったマッチ棒を少し薄く削って、透明アクリルパネルと正面パネルの間に挟み、さらにマイクロスイッチの角度を少したてて、透明アクリルパネルと正面パネルの間に隙間を作ったところ、くっつくことなく作動するようになりました。ちなみにマッチ棒の断面は2×2mmでした。削ったマッチ棒の厚さは1mm強でした。
新たな動物を対象とする場合、反応をどのように検出するか最も考え悩むところです。デンショバトの場合は、上記のペンギンと同じような仕組みでつつき反応を検出します。通常の実験ですと、つつくパネルは直径3cm前後の円窓です。今回のペンギンの装置では、キィのかたさをどれくらいにするか迷いました。カラスぐらいつつく力が強いと柔な素材で作ると壊されてしまいます。また、反応が弱いと、なかなか反応を検出することが出来ず、つつき反応を自動的に強化する(餌を与える)ことが困難になります。反応の力はある程度あることを想定して、マイクロスイッチとしては最も大きな部類に入るスイッチを使ったところ、ちょうどうまくいきました。ところが、上記のような想定外のことが起きたわけです。これまで、装置に水がかかる動物を対象としたことがなかったので、想定外の事態となったわけです。
反応が弱い対象動物の場合は、通常のマイクロスイッチではなく、フォトセル(光電素子)を利用したスイッチを使うことがあります。私がセキセイインコを最初に始めたときは、LED(発光ダイオード)をマイクロスイッチからのびた金属の棒に直接貼り付けて、点灯したLEDをくちばしでくわえて動かすように訓練して反応を検出していました。セキセイインコは、くちばしで押す力は弱いのですが、くわえて引っ張ったり、ひねったりする力はある程度あります。ただ、この方法だと、LEDが点灯しているかどうかの弁別実験は出来ても、形や写真などの視覚刺激の弁別実験には向いていません。刺激そのものへ反応させる方が弁別が早く進むからです。そこで、次に使用したものが、フォトセルでした。セキセイインコが十分はいることが出来る実験箱(5インチのフロッピィーディスクのアクリルケースを流用)には四角い窓が3個設けられ、そこからモニター画面を見ることができました。3個の四角い窓の上部には、それぞれ、グラスファイバーで赤外線を投射し、反射光を検出することが出来るセンサーを取り付けました。セキセイインコはつつかなくても、首やくちばしをその窓に入れるだけで反応することが出来ました。ビデオライブラリーのセキセイインコのオペラント条件づけ動画はこの装置です。
その後、 モニターそのものへの反応の検出が可能なタッチセンサーを利用するようになりました(近々論文が出版されます(1))。タッチセンサーには色んな種類がありますが、光電素子を利用したものを今は利用しています。実は、この装置も、ペンギンと同様な問題が生じることがあります。セキセイインコは、粟などの穀物を強化子として使用します。実験中、食べながら反応しますので、食べかすがセンサーの上に落ち、常時センサーを覆ってしまい、反応を検出できなくなることがあります。こういう場合は、その都度掃除が必要です。
このタッチセンサーを利用したシステムにおいても、予期せぬ反応が生じることがあります。あるセキセイインコが、実験中くるっと回転したところ、ちょうど後ろ向きになった時点で尾羽がセンサーに反応してしまい強化される(餌がもらえる)ということがおきました。それ以降、つつかないでくるくる回る反応をするようになりました。この回転反応もつつき反応同様、タッチセンサーをONにするので、同一のオペラント反応になります。この実験では、つつき反応の位置が重要でしたので、回転反応は問題行動になります。この問題行動をやめさせる手段として考えられるものは、画像処理システムを使うのは大がかりすぎますので、目で見ていて、回転したら強化を保留するように、実験者がスイッチを押すというやり方があります。ただ、これは、手間がかかりすぎます。手っ取り早い方法は、すこしかわいそうですが、尾羽の先をセンサーにふれないように切ってしまうというものです。セキセイインコの尾羽はそのうちまた生えてきます。今まで回転すると強化されていた(餌がもらえていた)のに、回転しても強化されない(餌がもらえない)ようになり、そのうち回転反応はしなくなります。この手続きは、結果的に回転反応の「消去」手続きになります。尾羽がまた生えてきた時点ではすでに、回転反応は完全に消去されていました。
動物のオペラント条件づけでは、マイクロスイッチをON/OFFさせる反応のみをオペラント反応とするわけではありません。ビデオカメラと画像処理システムを使ったもの(2)や、マイクロフォンを使ったものもあります。この研究については、また、後ほど機会を見つけて書いていきたいと思います。
(1)タッチセンサーを使った実験
Manabe, K. (2008). Control of Response Variability: Call and Pecking Location in Budgerigars (Melopsittacus undulatus). In Innis N. (Ed.) Reflections on Adaptive Behavior: Essays in Honor of J.E.R. Staddon, MIT Press.
(2)ビデオカメラと画像処理システムを利用した実験
(3)マイクロフォンと音声処理システムを利用した実験
移調(Transposition)
今回のペンギン実験の目的は、2つありました。1つ目は、ペンギンのスキナーボックスを用いたオペラント条件づけは始めての試みなので、装置や訓練方法を含めた方法論の確立でした。この点については、これまでの進捗状況の1~10までに報告してきたように、ほぼ確立されました。
二つ目の目的は、ペンギンの弁別能力を調べるというものです。弁別(Discrimination)とは、ある刺激と別の刺激を見分けたり、聞き分けたりすることを指します。しかし、ヒトの赤ちゃんと同様、動物も刺激の違いが分かるかどうかを言語を使って問うても、答えてはくれません。そこで、色んな方法を使って動物に「聞く」ということをやります。それらの中には、馴化ー脱馴化法などがありますが、オペラント条件づけを用いた方法もあります。今回の実験では、オペラント条件づけを用いて、ペンギンの長さ弁別を検討しました。それではどうやってペンギンが長さの弁別が出来るかどうかを調べるのかということですが、例えば、長い線と短い線を二つ提示して、長い線をつついたら強化される(餌がもらえる)が、短い線をつつくと強化されないというように、2つの線分に対するつつき反応の結果を変えてやります。オペラント行動は、3つの要因(先行条件ー反応ー結果)で変化します。弁別刺激が先行条件にあたります。長い線(正の弁別刺激:先行条件)をつついたら(反応)、餌がもらえる(正の強化:結果)。一方、短い線(負の弁別刺激:先行条件)をつついたら(反応)、何も起こらない(消去:結果)。この様な場合、もし、線の長さの違いを弁別できれば、長い線に対してのみつつき反応が生じ、短い線に対してはつつき反応は生じなくなります。ペンギンをこの様な条件で訓練を行った結果、長い線分のみに対してつつき反応が生じるようなりました。また、短い線分のみで強化される条件では、短い線分のみをつつくようになりました。このことから、ペンギンは長さの弁別が出来るということが分かりました。
これだけでは、あまりに当たり前すぎて面白くありません。今回はさらに、もう一つの興味がありました。それは、ペンギンは長さの弁別を行うとき、「相対的」な長さにもとづいて弁別を行うのか、あるいは、これぐらいの長さの線に対して反応するが、これぐらいだと反応しないというように、「絶対的」な長さにもとづいて反応するのかという興味です。
このことを確かめる方法として、訓練で用いた刺激とは異なる刺激を用いてテストしてみるやり方があります。下の図は、訓練に用いた刺激(1と2)のうち、強化される刺激(2)とそれよりさらに長い刺激(3)を同時に提示して、どちらを選ぶか検討する方法(テスト1)と、訓練に用いた刺激(1と2)のうち、強化されない刺激(1)とそれよりさらに短い刺激(0)を同時に提示して、どちらを選ぶか検討する方法(テスト2)です。テスト1では、もし、相対的に長い線を選択することを学習していれば3を選び、絶対的な線の長さを学習していれば2を選ぶはずです。テスト2では、相対的に長い線を選択することを学習していれば1を選び、絶対的な線の長さを学習していれば選択率は五分五分になる可能性があります。
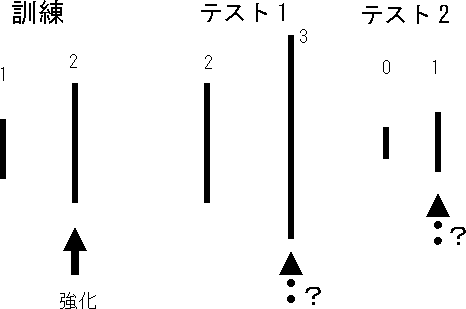
それでは、どうやって訓練に使用していない刺激を提示して選択させるかですが、プローブテストという方法を今回は用いました。プローブ(probe)とは「 探り針」のことで、通常の弁別訓練の中に出来るだけ分からないように、テスト試行を挿入して調べるやり方です。テスト試行では、いかなる反応に対しても結果を与えない消去法と、いかなる反応に対しても強化する強化法があります。今回は、訓練時の正反応に対する強化率を33%とし、残りの67%はクリッカー音だけ提示する条件性強化子を利用した訓練を行っていましたので、テスト試行では、いかなる反応に対してもクリッカー音だけを提示しました。条件性強化子を用いた強化法にあたります。
結果は、4個体中2個体で統計的に有意な確率で相対的な反応を行い、他の個体も相対的な選択傾向が見られました。ケープペンギンは、今回のような弁別訓練では相対的選択を行うということが言えると思います。この様に、相対的に選択する現象のことを移調(Transposition)と呼びます。これまで、移調はニワトリなどでも報告されています。
2個体のプローブテストの動画が下に掲載されています。前半は弁別訓練、後半は弁別訓練に4試行のプローブ試行が挿入されています。ソラは、長い線分へのつつき反応が強化され、ノッポはその逆です。
